1. 정의
하드웨어 프로비저닝이나, Replication, Software Update등 별도 설정이 필요 없는 완전 관리형 NoSQL Database Service입니다.
2. 구성
Tables

데이터들의 모음으로, 위 그림과 같이 People Tables에는 각각의 Person 정보들이 담깁니다.
Items
각각의 Tables는 0개 이상의 Items 을 포함합니다. Items는 attributes 들의 모음입니다. 위 그림에서 각각의 Person이 Items를 의미합니다.
Attributes
Items내의 각 구성요소를 의미합니다. 위 그림에서, PersonId, LastName, FirstName, Phone이 Attributes입니다.
Primary Key
Tables 생성 시, 이름과 함께 Primary Key 를 지정해야 합니다. Primary Key는 Tables 내의 각각의 Items를 고유하게 구별하는 ID 값과 같습니다.
*각 Primary Key 속성은 단일 값 형태여야 합니다. 즉, Nested Items 형태는 불가능 합니다.
- Partition Key
하나의 attribute로 구성된 Primary Key로, 저장되는 Items의 partition을 결정하기 위해 사용되는 Hash Function의 입력 값으로 사용됩니다.
*Partition Key만 존재하는 Tables에는 같은 Partition Key를 가질 수 없습니다.
- Partition Key and Sort Key
두개의 attribute로 구성된 복합 Primary Key로, 첫번째 attribute는 partition key 로 사용되고, 두번째 attribute는 sort key 로써 사용됩니다.
*Partition Key, Sort Key를 가지는 Tables에는 같은 Partition Key를 가질 수는 있지만, Sort Key는 다른 값을 가져야합니다.
*Partition Key, Sort Key를 가지는 Tables에 Partition Key로만 쿼리를 하게 되면, 해당 Partition Key를 가지는 모든 Items를 반환합니다. Sort Key 와 함께 쿼리를 하게 되면, 범위 검색이 가능합니다.
위 그림에서 Music Table은, Artist(partition Key), SongTitle(Sort Key)로 Primary Key를 구성하고 있습니다.
Secondary Indexes
한 개 이상의 Secondary Indexes를 Table에 설정할 수 있습니다.
Secondary Indexes는 Primary Key외 속성으로 쿼리를 가능하게 합니다.
- Global Secondary Index
Table에 설정된 Partition Key, Sort Key와 다른, Partition Key와 Sort Key로 이루어진 Index입니다.
- Local Secondary Index
Table에 설정된 Partition Key는 같지만, 다른 Sort Key를 가질 수 있는 Index 입니다.
앞서 Music Table에서는 Artist와, Artist, SongTitle 조합으로 쿼리를 할 수 있습니다. 만약 Genre 또는 Year등으로 쿼리를 하고 싶다면, 해당 Attribute를 이용해 Index를 생성해야 합니다.
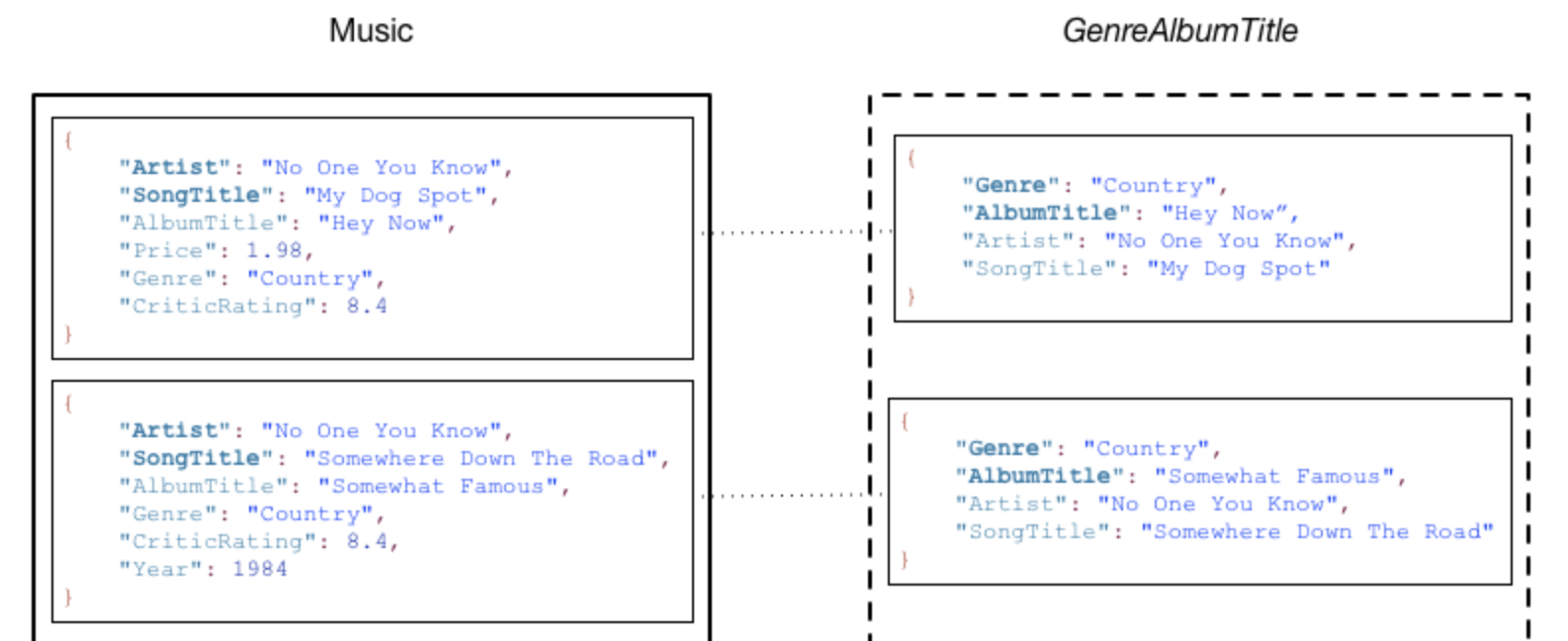
위 그림은, Genre, AlbumTitle로 Global Secondary Index를 생성한 예제입니다. Genre는 Partition Key, AlbumTitle은 Sort Key입니다.
모든 Index들은 기본 Table에 속합니다. 위의 GenreAlbumTitle 인덱스는 Music Table에 속합니다.
또한, DynamoDB는 인덱스를 자동으로 유지합니다. 기본 Table에 항목이 추가, 삭제 또는 업데이트가 발생하면 해당 Table에 속한 Index들을 모두 자동으로 업데이트 합니다.
Index를 생성할 때, 기본 Table에서 새로운 Index로 복사 또는 프로젝션할 속성을 지정합니다.
DynamoDB Streams
추가 기능으로, Table의 데이터 변경 이벤트를 포착하는 기능입니다. 이 기능을 활성화 하면, Table의 데이터 변경 정보를 Streams에 발행(?) 하게 되며, 다른 AWS 서비스들에서 해당 변경 정보를 구독하고 이에 따라 추가 처리를 하도록 구성할 수 있습니다. 자세한 정보는 공식 문서를 참조해 주세요.(https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.CoreComponents.html)
3. Data Type
Scalar Types
스칼라 타입은 정확히 한개의 값을 의미합니다. Number, String, Binary, Boolean, Null 등이 스칼라 타입에 해당합니다.
Document Types
List, Map 등이 Document Types에 해당합니다.
- List
정렬된 값 모음으로 대괄호([…]) 묵여있습니다.
ex)
FavoriteThings: ["Cookies", "Coffee", 3.14159]- Map
정렬되지 않은 name-value 쌍의 모음으로 중괄호({…})로 묶여 있습니다.
ex)
{
Day: "Monday",
UnreadEmails: 42,
ItemsOnMyDesk: [
"Coffee Cup",
"Telephone",
{
Pens: { Quantity : 3},
Pencils: { Quantity : 2},
Erasers: { Quantity : 1}
}
]
}Set Types
같은 종류의 타입을 모아놓은 타입입니다. Set 내의 모든 값은 유일합니다. 또한 Set 내의 순서는 보장 되지 않습니다.
*빈 Sets는 허용되지 않습니다. 하지만 Sets내의 빈 String, Binary 값은 허용됩니다.
4. 읽기 일관성
Eventually Consistent Read
결과적 일관성 읽기로, 일순간에 일관성이 보장되지 않은 즉, 오래된 데이터를 읽을 수도 있습니다.
Strongly Consistent Read
강력한 일관성 읽기로, 가장 최신의 데이터를 읽는 것을 보장합니다.
*강력한 일관성 읽기는 다음과 같은 단점이 존재합니다.
- Network 지연이 발생하는 환경에서 사용이 불가능합니다.
- Global Secondary Index에 대해서는 불가능 합니다.
- 결과적 일관성 읽기보다 더 높은 레이턴시를 발생시킵니다(느립니다).
5. Partitioning
Partitioning은 DynamoDB에서 스스로 관리하기 때문에, 별도로 설정할 필요가 없습니다.
Partition이 추가 되는 경우
- 기존 파티션이 지원할 수있는 것 이상으로 테이블의 프로비저닝 된 처리량 설정을 늘리는 경우.
- 기존 파티션이 용량을 채우고 더 많은 저장 공간이 필요한 경우.
Partition Key Design
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-partition-key-design.html
'AWS > Database' 카테고리의 다른 글
| AWS - RDS 생성 및 접속 (EC2 및 Onpremise 에서 접속) (0) | 2019.01.03 |
|---|---|
| AWS - 실습) RDS DB 다중 AZ (고가용성) (0) | 2018.11.21 |
| AWS - 이론) Database(데이터베이스) 서비스 (0) | 2018.11.19 |